Introduction
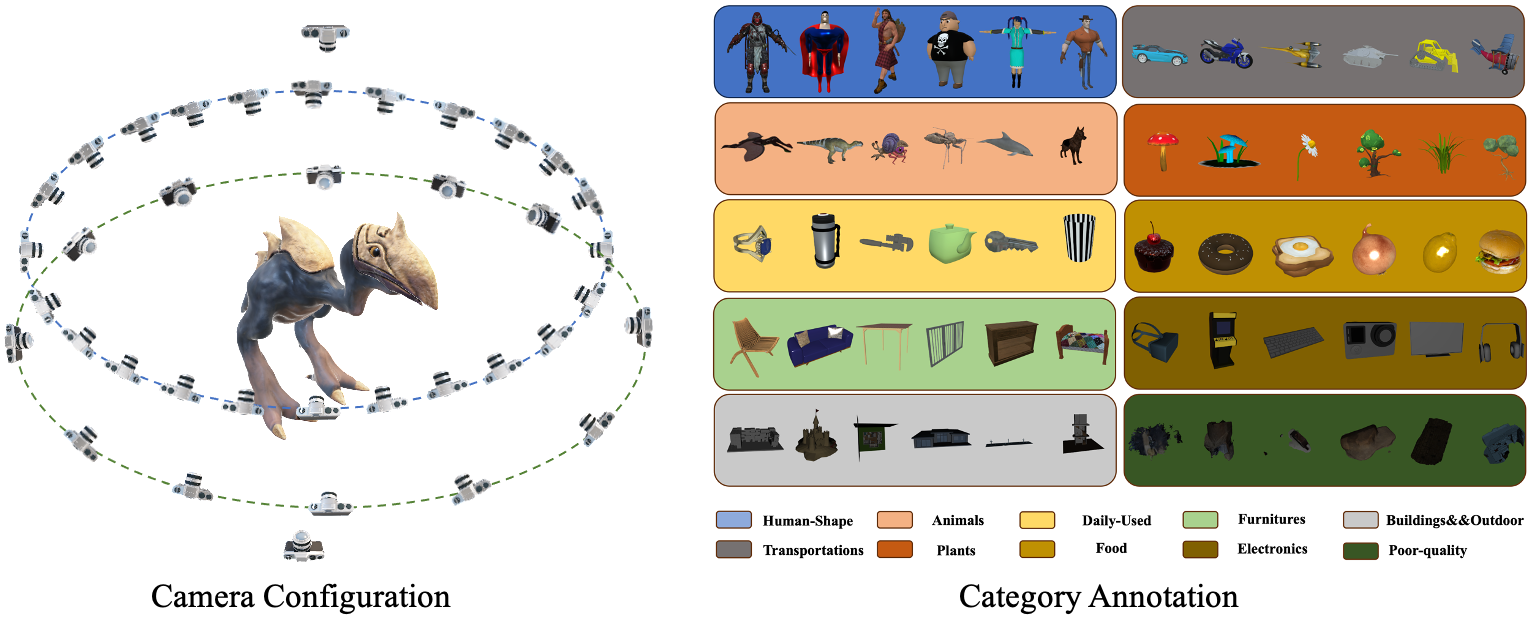
G-buffer Objaverse (GObjaverse) proposed in Sparse3D (ECCV2024) is rendered using the TIDE renderer on Objaverse with A10 for about 2000 GPU hours, yielding 30,000,000 images of Albedo, RGB, Depth, and Normal map. We proposed a rendering framework for high quality and high speed dataset rendering. The framework is a hybrid of rasterization and path tracing, the first ray-scene intersection is obtained by hardware rasterization and accurate indirect lighting by full hardware path tracing. Additionally, we using adaptive sampling, denoiser and path-guiding to further speed up the rendering time. In this rendering framework, we render 38 views of a centered object, including 24 views at elevation range from 5° to 30°, rotation = {r × 15° | r ∈ [0, 23]}, and 12 views at elevation from -5° to 5°, rotation = {r × 30° | r ∈ [0, 11]}, and 2 views for top and bottom respectively. In addition, we mannuly split the subset of the objaverse dataset into 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).